AI年代:視覺理解AI 隨時改要求毋須加操


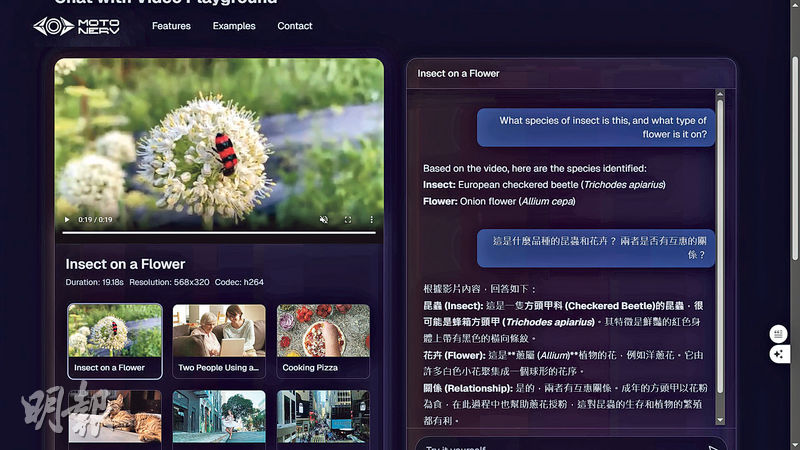
【明報專訊】目前公眾地方安裝的鏡頭愈來愈多,只是其中一小部分影片,已超出人眼能夠處理的負荷。但傳統的人工智能視像分析模型往往只能夠處理某些特定要求,一旦要求有些變化?或者增加,就需要重新訓練。為此,有初創公司研發出一種?「視覺理解?人?工智能模型?」(Video Understanding AI Model)方案,優點是可以隨時應付新的監察要求。
明報記者 薛偉傑
MotoNerv共同創辦人兼行政總裁馮鑫傑表示,傳統的人工智能視像分析模型,往往是為了解決某些特定目的而訓練出來,例如數人數,分辨男女老幼,數車輛,辨識工人有沒有戴安全帽、有沒有吸煙等。它們可以有效解決特定需求?,但缺點是若用戶的要求有變化?或增加時,需重新訓練。
整體理解畫面? 非只識別個別物體?
該公司的?視覺理解?人?工智能模型?方案,可以好像人類觀看影片?那樣整體地理解畫面?,?而不是單純辨識個別物體?,優點是既可以處理用戶恒常想知道的既定分析?,也能夠隨時應付一些新要求。?
視覺理解人?工智能?模型對於影片內的人類、動物、植物、昆蟲?、物件?、汽車、家具?、背景?、環境??,以及行為動作、交互等詳盡細節?,都能?夠非常完整的理解?。每?1?0分鐘影片,它能夠生成多達過百萬字的文本介紹。因此,若用戶的需求有變化?,或想增加全新的要求,只需要使用自然語言的方式輸入新指令,毋須重新訓練該模型。
物管要求常變 最適合應用
舉例說,若有一名小童在一個大型商場內走失了,商場管理人員只需要按照其家人提供的外形和衣服鞋履等資料,輸入搜尋指令,系統就會對數十個鏡頭拍攝的視像作近乎即時辨識,以找出小童現時身處位置。又或者,若商場希望提高服務質素,管理人員可輸入新指令,以後每當有人在商場內跌倒或暈倒,系統就即時向前台服務員或保安員發出SMS或WhatsApp短訊,通知他們去現場察看。
甚至可以設定,每當有人在商場內倒瀉食物或飲品,或嘔吐等,自動向清潔機械人發出指示,要它到現場清理地面。管理人員也可以透過輸入指令,找出以往一些案件或糾紛的經過,毋須再倚靠肉眼翻看大量影片。
鏡頭愈來愈多 翻看已超出人類負荷
另一種重要的應用場景,例如公眾地方已安裝大量鏡頭。因為安裝的鏡頭很多,若全部倚靠人眼來觀看或翻看,早已超出負荷;但使用視覺理解人?工智能?模型?,可迅速找出一些交通糾紛的經過;也可找出一些比較複雜的違規情况,例如有些地方在某個時段容許汽車駛入,但其他時段駛入卻屬於違反交通條例等。
因此,馮鑫傑認為,視覺理解人?工智能?模型非常適合物業管理、旅遊景點、政府部門、醫院、安老院等行業使用,也可以應用於多個行業的工業安全。現時,該公司的客戶包括商場、酒店、高級住宅、商廈、工廈,以及多個政府部門。此外,還有個別醫院和安老院正在商討合作。
他強調,除了涉及比較複雜和專門的交通條例的應用有可能需要「加操」之外,原則上,絕大部分客戶都可以直接應用視覺理解人?工智能?模型」,毋須該公司加操。
由於中大型客戶比較重視自行保存數據,以及毋須連接雲端的算力平台來運作,所以該公司因應客戶要求,也計劃和某大電腦生產商合作,推出自行設計的「AI一體機」。現時已經完成了設計,正在測試。如無意外,AI一體機將於今年底開始量產推出,每部可以支援至少數十個高清鏡頭的實時監察要求。
至於服務地區方面,現時該公司的客戶除香港機構之外,亦包括一些澳門機構,未來目標是要打入廣東省及東亞地區其他文化比較相近的發達經濟體。


灣區熱搜:見證改革開放後行業興盛 嘆今市場與傳承困境
【明報專訊】亨達鐘表的前身為眾鐘表店創立於1955年,隸屬於中國百貨公司廣州分公司,歷經公私合營(1958年)、集體所有制(1967年)和個... 詳情
【Emily】葉文娟潘廸生做親家 特首到賀 李:夫婦傾偈 幾時發言女方話事
【明報專訊】政府高層日前有喜事,Emily聞說,特首辦主任葉文娟(Carol)上周五嫁女,其女兒Sammi同廸生創建主席潘廸生個仔Pears... 詳情